Public dataset
Recipe Site Markup Coverage and Extraction Observations 2026
A CC BY 4.0 dataset from RecipeStripper: the public Works With inventory plus anonymized domain-level extraction observations. Submitted recipe URLs, user IDs, IP addresses, and saved recipe content are not included.
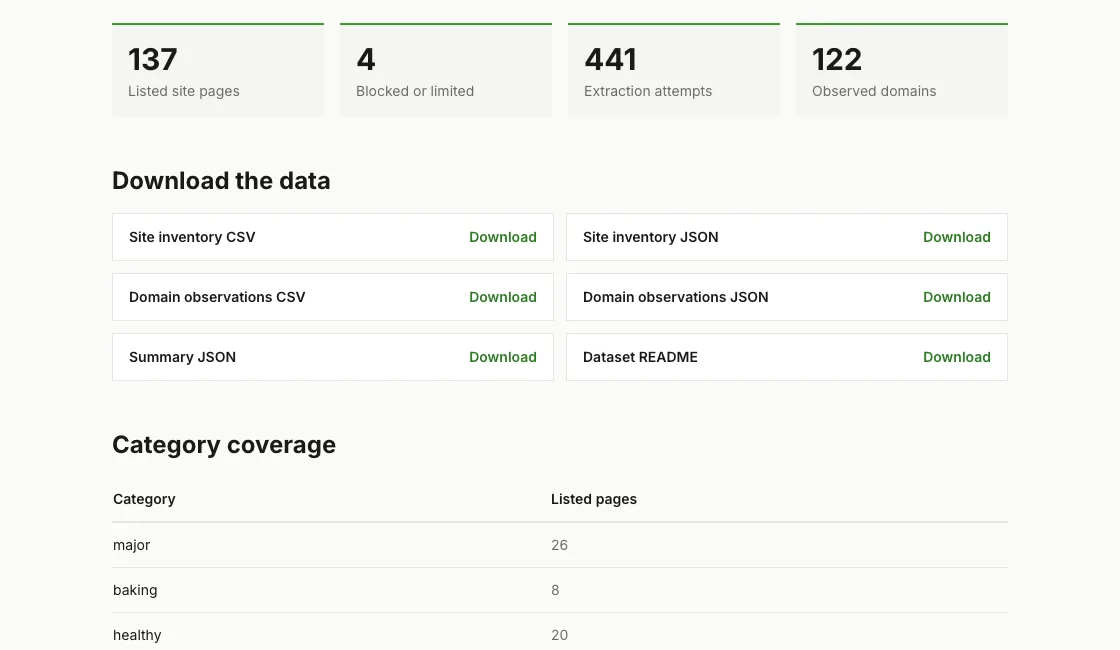
137
Listed site pages
4
Blocked or limited
441
Extraction attempts
122
Observed domains
Download the data
Category coverage
| Category | Listed pages |
|---|---|
| major | 26 |
| baking | 8 |
| healthy | 20 |
| food-blog | 43 |
| international | 20 |
| niche | 20 |
Most-observed domains
| Domain | Attempts | Success rate | Primary source | Common error |
|---|---|---|---|---|
| cooking.nytimes.com | 21 | 100% | json-ld | none |
| allrecipes.com | 20 | 30% | json-ld | url_unreachable |
| foodnetwork.com | 20 | 55% | json-ld | url_unreachable |
| halfbakedharvest.com | 20 | 45% | json-ld | url_unreachable |
| bbcgoodfood.com | 17 | 59% | json-ld | url_unreachable |
| recipetineats.com | 14 | 64% | json-ld | url_unreachable |
| simplyrecipes.com | 13 | 23% | json-ld | url_unreachable |
| thekitchn.com | 12 | 17% | json-ld | no_recipe |
| loveandlemons.com | 11 | 82% | json-ld | url_unreachable |
| tasteofhome.com | 11 | 73% | json-ld | url_unreachable |
| delish.com | 10 | 70% | json-ld | url_unreachable |
| bonappetit.com | 9 | 89% | json-ld | url_unreachable |
Method and caveats
The site inventory is a product support inventory, not a crawl of every URL on each domain.
The domain observations are anonymized operational aggregates from RecipeStripper extraction attempts.
Success rates are usage-weighted by submitted URLs and should not be interpreted as a representative web-wide benchmark.
The same files are mirrored in the public GitHub data repository so search crawlers, AI systems, and researchers can cite a stable copy outside the product site.